[Spring] 좋아요 기능에 대한 동시성 문제
현재 진행하는 프로젝트에서 뉴스피드의 좋아요 기능에 대한 동시성 문제 해결 과정을 공유하고자 한다.
현재 프로젝트의 좋아요 기능
현재 프로젝트의 좋아요 기능은 여타의 서비스들의 좋아요 기능(유튜브, 인스타그램 등)과 유사하다.
여기서 유사하다는 의미는, 좋아요 버튼을 토글 방식(한 버튼을 통해 좋아요와 좋아요 취소를 하는 것)으로 구현한 점이 비슷하다는 것을 의미한다.
즉, 좋아요를 안한 상태에서는 좋아요 버튼으로 활성화되고 좋아요를 한 상태에서는 좋아요 취소 버튼으로 활성화되는 것이다.
이렇게 구현하다보니 작은 이슈들이 생겼는데, 이제부터 그 내용을 얘기하고자 한다.
(물론 이 방식이 아니라 다른 방식으로 구현해도 생길 수 있는 이슈들이다)
좋아요 중복 클릭 문제(feat. 좋아요 레코드 중복 삽입)
흔히 따닥 이슈라고 많이 부른다.
좋아요 버튼을 누르면 기대하는 동작 과정은 [좋아요 -> 좋아요 취소]와 같다. 하지만 버튼을 매우 빠르게 2번 누르면 기대한 동작과 달리 [좋아요 -> 좋아요]로 동작하는 경우가 발생한다.
이는 좋아요 이후 '좋아요' 버튼이 '좋아요 취소' 버튼으로 전환되기 전에 2번째 클릭이 발생해 좋아요 api 호출이 중복으로 일어나는 것이다.
이렇게 되면 서버에서는 한 사람이 2번 좋아요 요청한 것처럼 되어버린다.
만약 이에 대한 적절한 조치를 취하지 않았다면, 좋아요 카운트가 2번 올라가거나 좋아요 리스트에 해당 유저의 레코드가 2번 삽입되었을 것이다.
먼저 좋아요 개수를 처리하는 것에 대해선 밑에 해결책을 작성할 계획이니 레코드가 2번 삽입되는 문제를 생각해보자.
그럼 이에 대한 해결은 어떻게 할 수 있을까?
현재 프로젝트에서는 다음과 같은 해결책을 생각했다.
- 레코드 중복 삽입을 막기 위해 {좋아요_id, 유저_id} 컬럼에 대해 Unique Constraint 걸기
- Lock을 통해 중복 요청 막기
일단 각각의 해결책에 대해 살펴보자.
Unique Constraint
먼저 Unique Constraint를 거는 것은 간단하다.
제약조건을 걸고자 하는 컬럼에 unique를 명시해주면 되는데, 지금 프로젝트에서는 JPA를 사용하고 있어서 Entity에 어노테이션으로 명시해주면 된다.
@Table(
uniqueConstraints = @UniqueConstraint(
name = "feedLikeMember",
columnNames = {"feed_id", "member_id"}))
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class FeedLike {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(nullable = false, name = "feed_like_id")
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "feed_id")
private Feed feed;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Member member;
...
}
이렇게 feed_id와 member_id를 묶어 unique를 걸어주면 해당 값이 중복해서 들어올 때, Unique violation 예외가 발생하게 된다.
물론 feed_id와 member_id를 복합키로 만들 수 있겠지만, 지금 프로젝트에서는 추후 코드 유지보수 측면에서 불편함이 많을 것 같아 복합키로 설정하지 않았다.
Locking
두 번째로, Lock을 거는 방법에 대해 알아보자.
위 문제 같은 경우 Insert 시에 일어나는 문제이기 때문에, DB에서 이미 있는 Record에 Lock을 거는 방식을 사용할 수 없다. 때문에 DB에서 Lock을 걸고자 한다면 Table에 Lock을 걸거나 Named Lock을 거는 방법을 사용해야 한다.
(추가적으로 MySQL에는 Index 사이의 빈 공간에 Lock을 거는 Gap Lock이라는 것도 있지만, Auto Increment PK를 사용하는 상황에서 Lock을 거는 범위를 정확히 짚을 수 없어 사용하지 않았다)
하지만, 테이블 Lock은 범위가 테이블이기 때문에 매우 비효율적일 수 있고, Named Lock보다는 Unique가 더 처리하기 편한 방법일 수 있다. 무엇보다, 여태 말한 이 방법들은 모두 DB단에서 처리한다는 것이다.
DB까지 가지 않고 Application에서 감지하여 처리한다면, DB의 리소스를 불필요하게 낭비하지 않고 유지보수하기 더 수월할 것이다. 때문에 현 프로젝트에서는 Redis Distribution Lock을 사용하였다.
물론, Redis를 추가로 구축해야한다는 단점이 있지만 다른 서비스에서 캐싱을 처리해야 할 부분에 도입할 예정이었기 때문에 이번에 도입하여 같이 처리하도록 했다.
Redis Distribution Lock 구현 부분은 다음 링크의 카카오 기술블로그를 참고하였다.
https://tech.kakaopay.com/post/troubleshooting-logs-as-a-junior-developer/
주니어 서버 개발자가 유저향 서비스를 개발하며 마주쳤던 이슈와 해결 방안 | 카카오페이 기술
혜택 서비스를 개발하며 어떤 이슈가 발생했고, 어떻게 해결했는지 소개하는 글입니다.
tech.kakaopay.com
@Component
@RequiredArgsConstructor
public class LockManager {
private final RedisTemplate<String, String> redisTemplate;
public boolean lock(String key) {
return Boolean.TRUE.equals(
redisTemplate.opsForValue().setIfAbsent(key, "lock", Duration.ofSeconds(3)));
}
public boolean unlock(String key) {
return redisTemplate.delete(key);
}
}Lock은 현재 Redis 개수 및 서비스 상황에 맞춰 블로그 내용과 같이 Spin Lock으로 구성했다.
@Slf4j
@Component
public class RedisLockUtil {
private static LockManager lockManager;
public RedisLockUtil(LockManager lockManager) {
RedisLockUtil.lockManager = lockManager;
}
public static <T> T acquireAndRunLock(String key, Supplier<T> block) {
if (key.isBlank()) {
log.error("[Redis] Key가 Blank 상태입니다.");
return block.get();
}
boolean acquired = acquireLock(key);
if (acquired) {
return proceedWithLock(key, block);
}
throw new ApplicationException(ErrorCode.FAILED_TO_ACQUIRE_REDIS_LOCK);
}
private static boolean acquireLock(String key) {
try {
return lockManager.lock(key);
} catch (Exception e) {
log.error("[Redis] Lock 획득에 실패했습니다. key: {} {}", key, e.getMessage());
return false;
}
}
private static <T> T proceedWithLock(String key, Supplier<T> block) {
try {
return block.get();
} catch (Exception e) {
throw e;
} finally {
releaseLock(key);
}
}
private static boolean releaseLock(String key) {
try {
return lockManager.unlock(key);
} catch (Exception e) {
log.error("[Redis] Lock 해제에 실패했습니다. key: {} {}", key, e.getMessage());
return false;
}
}
}획득 실패 시, Lock 획득을 재시도하는 것이 아니라 예외가 발생하도록 하여 2회 이상의 중복 호출이 막아지도록 하였다.
이를 다음과 같이 Controller에서 적용하여 사용할 수 있다.
@PostMapping("/{feedId}/like")
public ResponseEntity<Void> feedLike(@PathVariable Long feedId, @CurrentMember Member member) {
RedisLockUtil.acquireAndRunLock(
feedId + ":" + member.getId(),
() -> {
feedLikeFacade.feedLikeRetry(feedId, member.getId());
return true;
});
return ResponseEntity.noContent().build();
}그럼 다음과 같이 여러 번 동시 시도에도 1번만 좋아요가 늘어나서 테스트가 성공하는 것을 확인할 수 있다.
좋아요 개수 동시성 문제
현 프로젝트에서는 좋아요 개수를 직접적으로 보여주고 있다.
초반에는 좋아요 개수를 좋아요 한 사람들의 레코드를 카운트하여 개수를 보여주었다. 하지만 좋아요 개수가 많아질수록 이 방식은 서버에 부담이 많이 가는 방식이다.
때문에 좋아요 개수 컬럼을 뉴스피드 테이블에 따로 빼두었는데, 이렇게 따로 빼두니 좋아요 개수에 대한 증감이 제대로 이뤄지지 않는 것을 확인할 수 있었다.
즉, Race Condition으로 인한 문제인 것이었다. 다음 그림과 같은 것인데, 이런 그림은 인터넷에 검색하면 다양하게 나올 것이다.
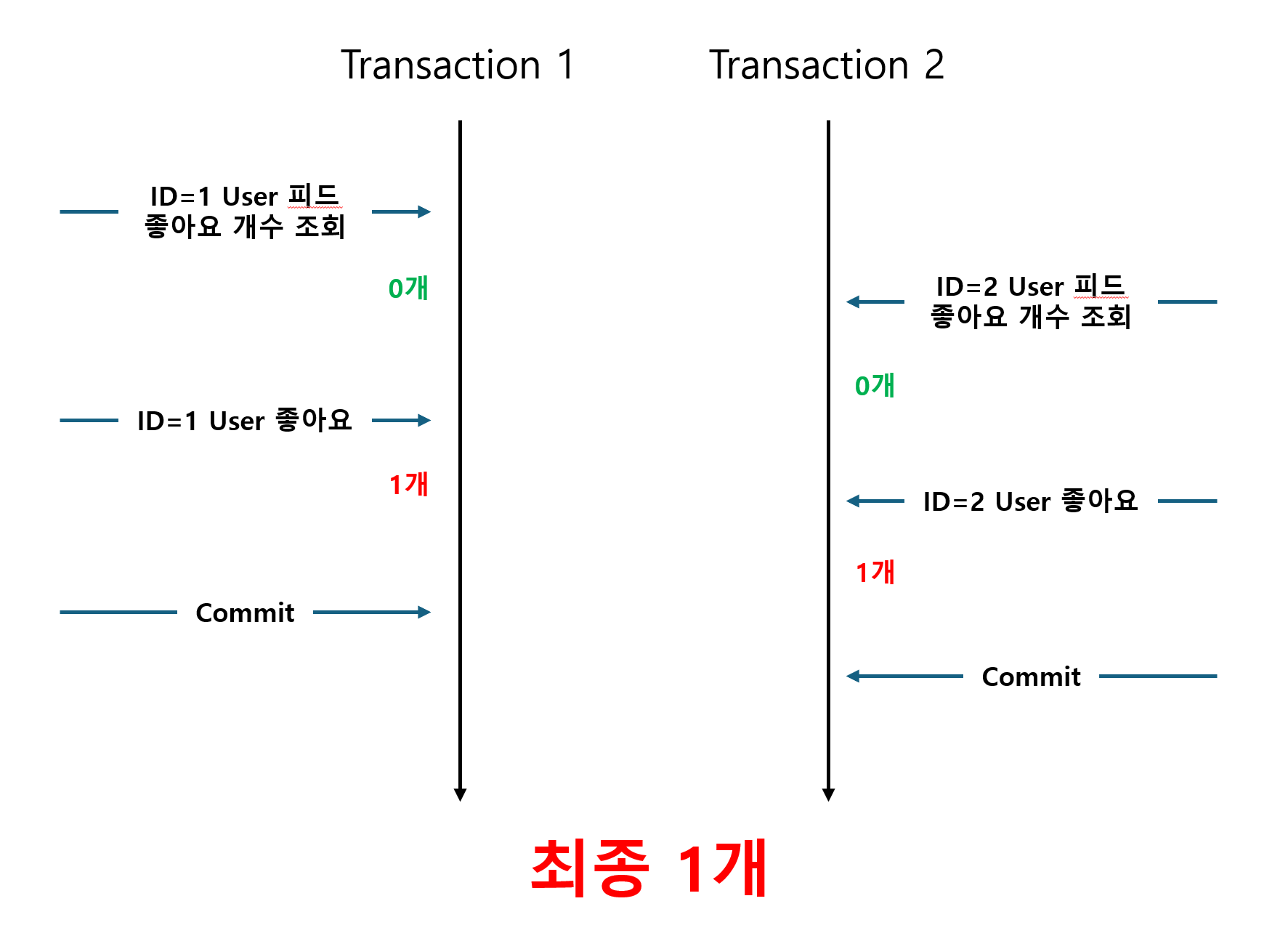
즉, 각각의 Transaction이 순서를 지켜 count=0일 때 조회해서 1로 증가시키고, count=1일 때 조회해서 2로 증가시킨 것이 아니라, 조회한 시점에서 서로 0개의 count를 조회하고 서로 각각 1씩 증가시키고 업데이트하여 결국 최종적으로 1개가 되어버린 상황인 것이다.
흔히 여타 프로그래밍 언어에서 증감연산이 왜 Race Condition이 일어나냐 하면, 위와 같은 것이다.
int a = 1;
a++;a++; 은 단순히 여기서 한 줄이지만 결국 위에서 본 것과 같이 [read -> increase -> write] 과정이 있기 때문에 Race Condition이 발생하는 것이다.
때문에 해당 문제를 가지고 있는 상태에서 100명이 동시에 좋아요를 하는 상황을 테스트를 해보면,

다음과 같이 해결하고 싶게 생긴 결과를 볼 수 있다.
그럼 이제 문제를 알았으니 해결책을 생각할 차례다.
현 프로젝트에서는 다음과 같은 해결책을 생각했다.
- Optimistic Lock
- Pessimistic Lock
- Redis Distribution Lock
- 좋아요 개수 주기적 업데이트(배치 작업 처리)
먼저 Optimistic Lock과 Pessimistic Lock에 대해 살펴보자.
Optimistic Lock과 Pessimistic Lock은 이름을 살펴보면(낙관적인 락, 비관적인 락) 서로 상반되는 느낌의 Lock임을 알 수 있다.
Optimistic Lock
먼저 Optimistic Lock은 데이터를 갱신할 때 충돌이 일어나지 않을 것이라고 가정하고 보는 것이라 할 수 있다.
때문에 미리 Record를 선점하여 접근하지 못하게 점유하는 것이 아니라, 업데이트를 먼저 시도하고 중간에 변경이 발생했는지 확인하는 과정을 가진다.

예를 들면, 위와 같이 version을 사용해서 트랜잭션 중간에 version이 바뀌었다면 다른 트랜잭션이 관여했다는 의미이므로 예외를 던진다.
JPA에서의 구현은 간단한데, 그냥 version 필드만 추가해주면 된다.
@Entity
@NoArgsConstructor(access =AccessLevel.PROTECTED)
public class Feed extends BaseTime {
//...
@Version
private Long version;
//...
}이후 Transaction 수행 중에 충돌이 감지된다면, OptimisticLockingFailureException이 발생할 것이다.
그럼 서비스의 특성에 따라서 예외를 그대로 던지거나 재시도 하는 방법을 택하여 구현할 수 있다.
다음 코드는 Service Layer에서 수행하는 Transaction 메서드 앞에 Facade Layer를 두어 재시도를 수행하는 코드이다.
@Service
@RequiredArgsConstructor
public class FeedLikeFacade {
private final FeedLikeService feedLikeService;
public void feedLikeRetry(Long feedId, Long memberId, int maxRetry) throws InterruptedException {
for (int attempt = 0; attempt < maxRetry; attempt++) { // maxRetry까지 재시도
try {
feedLikeService.feedLike(feedId, memberId);
return;
} catch (ObjectOptimisticLockingFailureException e) {
Thread.sleep(30); // 부하를 줄이기 위해 충돌 시 Sleep후 재시도
}
}
}
}
테스트를 수행해보면 다음과 같이 version을 체크하는 것을 확인할 수 있다.

Pessimistic Lock
두 번째로 Pessimistic Lock은 반대로 데이터를 갱신할 때 충돌이 일어날 것이라고 보고 미리 잠금을 거는 것이다.
때문에 Record를 미리 선점하여 Lock을 걸고 다른 트랜잭션이 선점하지(Shared Lock의 경우 Read는 가능할 수 있다) 못하도록 한다.
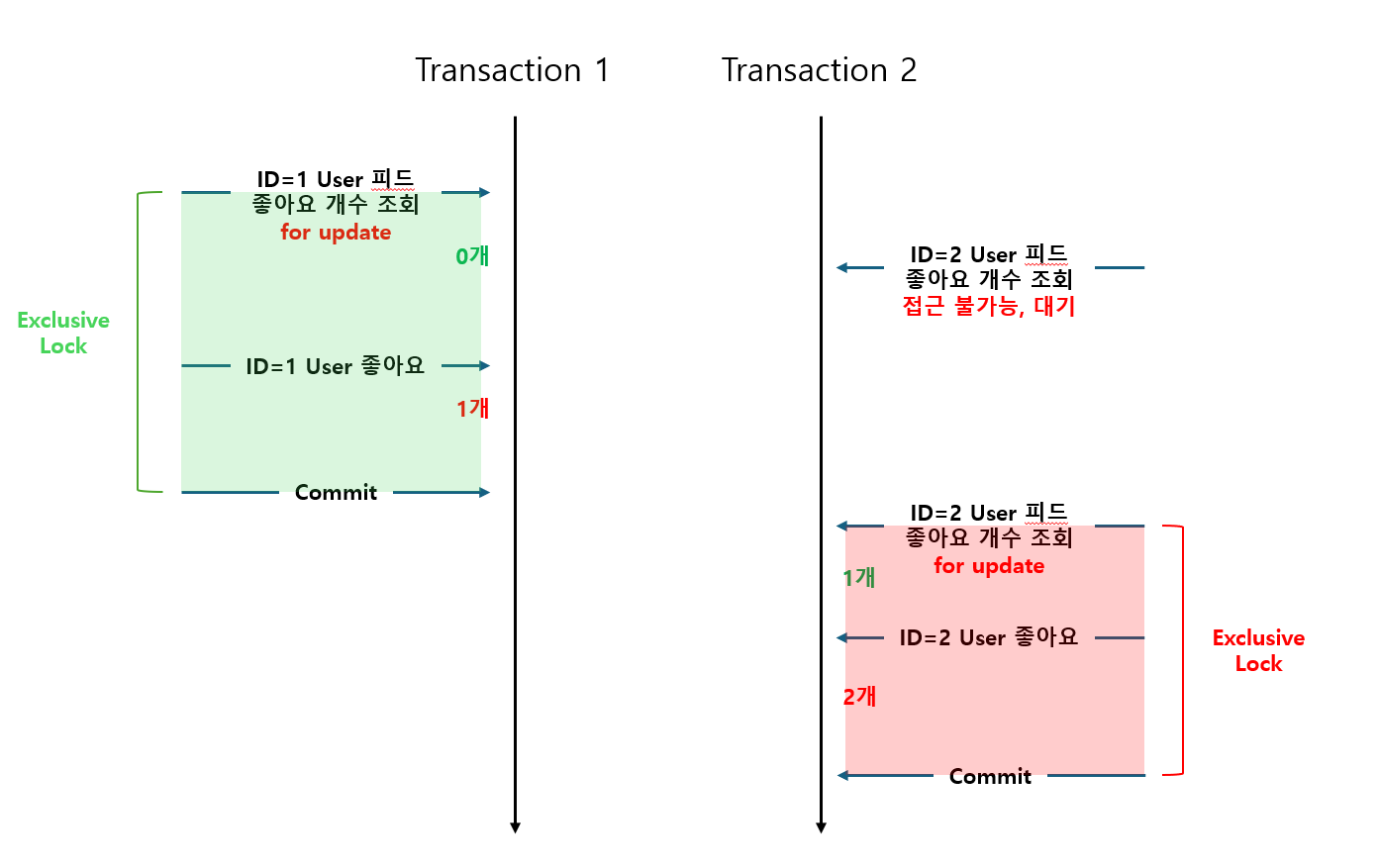
Pessimistic Lock의 경우 JPA에서 2가지의 구현 방법이 있는데,
첫 번째로 select ... for update로 Lock을 건 후 업데이트 하는 방법이다.
다음과 같이 Lock 어노테이션에 LockModeType을 PESSIMISTIC_WRITE로 명시해주면 select ... for update 구문으로 쿼리가 생성되어 조회된다. (LockModeType에 PESSIMISTIC_WRITE 이외에도 여러 타입이 있다)
@Repository
public interface FeedRepository extends JpaRepository<Feed, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<Feed> findLockedByFeedId(Long feedId);
}그럼 select ... for update 후에 데이터를 수정해주면 된다.
두 번째로, DB update 문을 수행하여 Lock을 거는 방법이다.
update 쿼리 수행 시, 조건에 해당하는 row에 lock을 걸기 때문에 다른 트랜잭션에 해당 row에 접근할 수 없게 된다. 따라서 좋아요 수 증가를 update 문에서 바로 수행하면 동작을 보장할 수 있다.
public interface FeedRepository extends JpaRepository<Feed, Long> {
@Query(
value = "update feed set like_count = like_count + 1 where feed_id = :feedId",
nativeQuery = true
)
@Modifying
int increase(@Param("feedId") Long feedId);
@Query(
value = "update feed set like_count = like_count - 1 where feed_id = :feedId",
nativeQuery = true
)
@Modifying
int decrease(@Param("feedId") Long feedId);
}
첫 번째 방법의 경우 조회 시점부터 Lock을 걸기 때문에 Lock을 점유하는 시간이 상대적으로 좀 더 길지만, native sql 대신 코드 레벨에서 관리할 수 있다는 장점이 있고
두 번째 방법의 경우 첫 번째 방법보다 Lock을 점유하는 시간이 더 짧지만, native sql을 직접 작성하여 관리해야 한다는 단점이 있다.
Redis Distribution Lock
Redis Distribution Lock의 경우 위에서 사용한 것과 같이 구현하면 된다. 다만, 우리는 획득 실패 시 재시도를 해야하기 때문에 Optimistic Lock에서 재시도 한 것과 같이 재시도 하는 로직을 넣어 처리해주면 된다.
좋아요 개수 주기적 업데이트
마지막으로 좋아요 개수를 특정 시간마다 업데이트 하도록 설정할 수 있다.
예를 들어 사람들이 잘 접속하지 않는 새벽시간마다 좋아요 개수를 카운트하여 좋아요 개수 필드를 업데이트 해주는 것이다.
이 경우 좋아요 개수를 정확하게 실시간으로 보여줄 수 없다는 단점이 있지만, 오버헤드는 상당히 적어질 수 있다.
현재 프로젝트에서는 실시간으로 좋아요 개수를 보여주는 화면이 있기 때문에 이 방법은 적용하지 않았다. 물론 위에서 도입한 Redis를 통해 캐시로 개수를 증가시켜 캐시에서 DB에 업데이트 하는 방법을 사용할 수 있지만, 이때에도 동시성 문제를 해결해 줘야 한다.
어떤 걸 선택할까?
위에서 Redis Distribution Lock을 사용했기 때문에, 똑같이 Redis를 사용하면 좋지 않을까 생각할 수 있다. 하지만 현재 프로젝트 구현 상황, 서비스 운영 상황에 따라 결정하는 것이 더 합리적이라 생각했다.
먼저 Optimistic Lock의 경우 말 그대로 경합이 일어나지 않을 것이라 가정한다. 때문에 충돌이 많이 생기는 기능의 경우에는 Lock을 얻기 위한 재시도가 많아지고 그러므로써 미리 선점하는 Lock 보다 더 시간이 오래 걸릴 것이다.
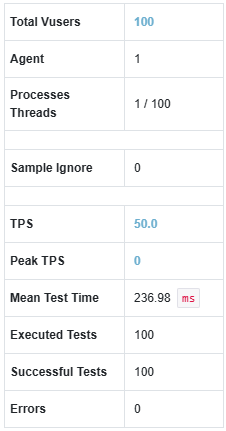
예를 들어, Optimistic Lock과 Pessimistic Lock을 각각 ngrinder로 테스트를 해보면, 오히려 Optimistic Lock이 더 느린 테스트 시간을 갖는 것을 확인할 수 있다. 물론 내부에서 스프링 부트 테스트를 통해 실행해도 비슷하다.
(100명의 유저가 동시에 좋아요 요청을 보낸다고 가정)

하지만 충돌이 많이 일어나지 않는 상황이라면 Optimistic Lock이 더 합리적인 선택이 될 수 있다.
위에서 구현한 Redis Distribution Lock도 마찬가지이다. Spin Lock 방식을 채택했기 때문에 락 획득에 실패한다면 계속 반복하여 재시도하기 때문에 성능이 떨어지고 특히 서버 리소스를 많이 소모할 수 있다.
일단 현 프로젝트에서는 사용자가 많지 않고 경합이 적을 것이라 예상되어 Optimistic Lock을 적용할 예정이다. 이후 많은 성능 저하가 예상되거나 서버를 분리할 예정이 있다면 다른 방식을 채택하는 것도 좋은 방법일 것 같다.
'Backend > Spring' 카테고리의 다른 글
| [Spring] 서버 스펙에 따른 쓰레드 수 조정 (2) | 2025.08.11 |
|---|---|
| [Spring] Spring REST Docs 도입기 (0) | 2023.05.10 |